
Legal AI needs memory that is held to a fiduciary standard, sets out what that takes, and flags where we want practitioners’ input.
Co-authored by Shishir Kapoor
Highlights
- General-purpose AI memory remembers your preferences, but it can’t tell good law from stale, keep one matter’s data out of another, or know which instruction outranks which.
- The authority that would settle those questions above isn’t something it owns.
- Legal AI memory must meet fiduciary standards: grounding data in current authority and isolating by matter.
Legal AI doesn’t need a better memory of facts. It needs memory built to a fiduciary standard that is grounded in current law, separated by matter, and aware of how past choices turned out.
Most memory tools on the market remember your preferences and feed them back. That helps, but they only ever draw on your own data, with no trusted authority to check it against.
Preferences are the easy part. What’s hard is memory of how you actually work, grounded in authority the provider owns end to end. Together, those let the system create higher quality drafts grounded in data from a trusted authority oriented to your ways of work.
Jump to ↓
How agentic memory works today, and where it stops
Why general agentic memory fails a fiduciary duty
The agentic memory that legal needs
Grounding: authority we own end to end
Deterministic walls: trust without trusting the model
How we’re thinking about it, and where we want your input

The problem
Open any legal AI assistant with no memory and the pattern repeats. The lawyer pastes the same context they gave it last week: the parties, the posture, the judge’s habits, the side they’re on, the risk tolerance, the templates the team prefers. The model is capable of the work but it simply doesn’t know what the lawyer already told it, on this matter or in another window, a month ago.
The fix is agentic memory. But memory for legal AI is not the same problem as memory for a general-purpose chatbot. The version the market is shipping remembers your personal preferences and carries them forward, and that is worth having. However, it is not enough, because the constraint here is mapping to a trusted standard, not a storage gap.
Legal work runs on duties: to keep a client’s confidences, to act on current law, to know which obligations outrank which. Memory a lawyer can rely on has to meet them. Call it fiduciary-grade agentic memory: the standard we hold professional AI to, applied to the memory layer.
Better recall of facts isn’t the goal. General tools, and the legal AI assistants now on the market, only personalize outputs; a fiduciary standard asks for more.
How agentic memory works today, and where it stops
Memory is no longer a novel idea. A wave of memory layers now sit in front of chat assistants and coding agents: the built-in memory in ChatGPT and Claude, and open memory frameworks, with a growing research literature surveying how they work. The pattern is similar: read an interaction, extract the semantic facts, make them retrievable, and reconcile what’s stored so it neither bloats nor contradicts itself.
Some build a bi-temporal knowledge graph that tracks when each fact held and invalidates stale ones instead of discarding them. Others impose schema-based structure on what gets written. Still others lean on vector recall with recency decay, or hybrid stores that do several of these at once. The approaches keep multiplying.
So the real question isn’t just “flat list versus graph,” or even “static versus temporal” — those are already table stakes. What’s missing, and what actually matters for legal, is how memory is grounded into trusted authority.
Every general layer grounds into the user’s own world, their conversations, documents, and any data fed into it. That works for an assistant recalling your preferences or an agent recalling your context. That context is essential raw material, but grounding only into it, with nothing authoritative to resolve against, is the wrong foundation for legal work.
A general layer is built for plausible recall, and for most uses plausible is enough. If it decides you prefer morning meetings because you happened to book a few early ones, the cost of being wrong is a calendar invite you move. That low cost of error is what lets these systems capture freely and reconcile loosely since nothing downstream breaks when they’re slightly off. Legal work affords no such margin. A general layer has no notion of privilege, no sense of which fact outranks another, and, most of all, no trusted authority to resolve a citation or clause against. It can tell you what was said, but it can’t tell you whether the case is still good law, because the thing that would know is authority it doesn’t own.
Why general agentic memory fails a fiduciary duty
Every way general memory falls short is, in legal terms, a duty it can’t discharge. Each one is answered later, point for point. Four stand out.
Each fiduciary duty maps to an answer
General memory can’t meet these obligations on its own — fiduciary-grade memory answers each one.
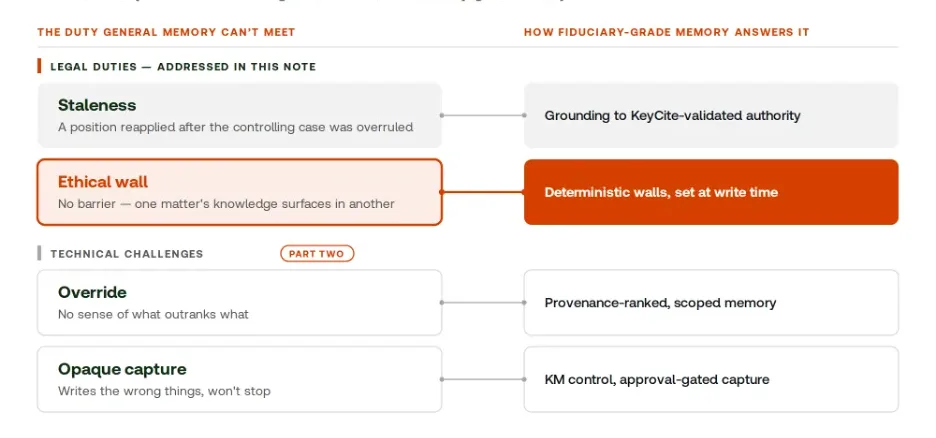
Staleness
A memory layer recalls a position from six months ago and reapplies it to a record that has since moved: the controlling case overruled, the rule amended. A store that only remembers has no way to notice; the duty to act on current law lives within a grounded authority.
Ethical wall
This is the one of legal teeth. A general layer has no information barrier; nothing stops one matter’s knowledge from surfacing in another. In United States v. Heppner, a criminal defendant’s unguided exchanges with a public, consumer-grade AI tool were held not privileged. The court found no attorney-client relationship, no reasonable expectation of confidentiality, and no work product prepared at counsel’s direction, and expressly left open that counsel-directed use of a confidential tool might qualify.
What followed was not that the tool was “AI” but where the data went and who could reach it. The lesson for agentic memory, where data lives and who can reach it is a legal question in its own right, not a setting.
Override and Opaque capture
While staleness and the ethical walls represent legal complexities, ‘override’ (resolving conflicting instructions) and opaque capture (managing autonomous memory writing) present complex technical challenges of their own. Because these deal heavily in the underlying architecture of agentic memory, we will explore both of these in detail in part two of this technical note.
The agentic memory that legal needs
Two kinds of memory matter here, and they are not equal.
- One personalizes what the assistant produces
- The other captures how the work is done and how it turned out
The terms are borrowed, loosely, from cognitive science, which has long separated semantic memory, what we know, from procedural memory, how we do things.
The first is the easy part. The second is where the value is. Both rest on the same foundation, trusted authority, and both feed the same output: proven methods across enough matters to become durable skills.
Semantic memory: preferences, done right
Preference memory is the easy half: style, tone, posture, the playbook a matter follows. It is what the consumer assistants already do, and what the leading legal tools are now adding: remember that this client wants plain-English summaries, that the lead attorney never hedges, that this deal runs on the buy-side playbook. Useful, but not a difference-maker on its own.
What makes it fiduciary-grade isn’t that a human is in the loop. Every serious vendor claims some version of that. What matters is where the loop sits.
Preferences attach to the function that already governs legal knowledge:
- Knowledge manager (KM)
- Professional support lawyer (PSL) at a firm
- Legal-ops and KM function in a department
The lawyer seeds the preferences that matter, the system surfaces how they drift over time, and nothing is promoted without an approval that function controls.
Precedence works the same way. When instructions conflict, the higher-ranked source wins. Senior counsel outranks a passing aside; a reviewed final outranks an early draft. That answers the override failure from earlier.
Procedural memory: the part nobody has built yet
The asset that grows with use is procedural memory. This type of memory is the way a lawyer actually does the work, related to the choices they made and what followed after. A senior litigator doesn’t just know the law, they have their own way of working, such that they know that on a personal-jurisdiction motion they check the controlling cases’ negative treatment first, then the judge’s record on that motion type, then the persuasive authority the opponent will cite.
That judgment took years to build and is hard to teach. Single-shot or even iterative chat captures the answer it produced. It does not capture the pattern that produced it, and it never records what happened next.
Getting there is a two-step move. The first is an episode: a faithful trace of a single run, including the retrievals, checks, and edits the agent made on this matter, and what followed each choice (whether the clause survived to signing, whether a reviewer kept or reversed it, or whether a position had to be walked back). One episode is one story, and it isn’t yet knowledge.
Procedural memory is what forms when those episodes start to accumulate, think the patterns across multiple traces. It is the reinforced “how-to” that says this method, run this way, is the one that holds. It’s the difference between remembering that a clause survived once and knowing this drafting approach survives to signing nine times in ten.
That consolidation is also what model weights can’t do alone. They can produce a draft that’s plausible, but they can’t weigh a recommendation against how comparable choices have actually played out, or predict how this one is likely to land. They generate but can’t keep score.
Procedural memory: the pattern across episodes, surfaced as a prediction
Individual runs and how they turned out consolidate into a reinforced “how-to” — which the agent proposes, never auto-applies.
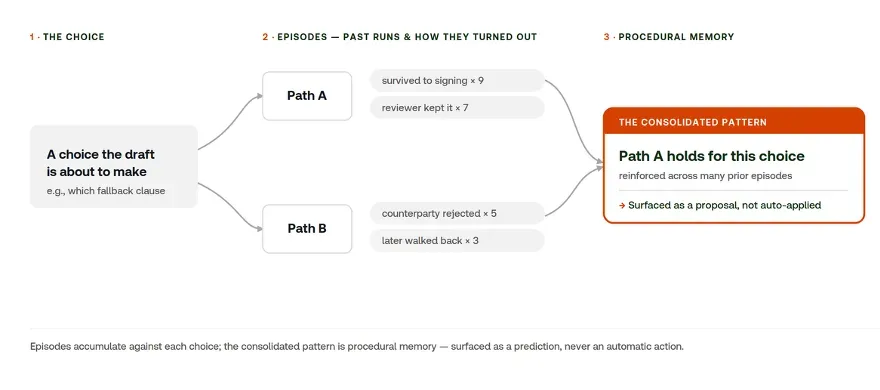
Procedural memory to this point is implicit, a probabilistic pattern the system learns and the agent draws on. The last step of this is to make it explicit. Once a method has proven itself across enough matters, it can be promoted into a plain-text research pattern: a SKILL.md a lawyer can read and review, gated behind an approval the knowledge manager controls and versioned so a given matter always runs against a known revision. The pattern stays stable and auditable while the specifics come from the case.
The payoff is institutional. A promoted pattern improves the next matter, and it puts the firm’s best-practiced method into a form the lawyers coming up behind can read and learn from. Knowledge that usually walks out the door with the senior who held it.
Figure 3. A promoted research pattern, generated through memory
Grounding: authority we own end to end
Traditional memory systems extract raw strings, and a string means little on its own. Grounding is the step that resolves those strings to trusted authority, so what the memory holds is a connected concept rather than loose text that happens to sit near a query.
That is the line between memory a lawyer can rely on and plain semantic search that simply returns similar passages or phrases. This grounding gives the agent canonical nodes it can reason over, across matters and against trusted authority. This allows the system to reliably identify entries are about the same thing, because it resolved them to the same authority rather than guessing from surface text.
“The 12(b)(2)” in one note and “motion to dismiss for lack of personal jurisdiction” in another are the same point of law, and a memory worth trusting normalizes both to the same classification, controlling cases, and good-law signal, not to a passage that merely reads similar. Without that, the memory store just accumulates plausible-looking text with no way to tell which entries belong together.
This is why a general-purpose memory system can’t bolt grounding onto it. A defined research pattern can only execute if it can resolve to authority, and authority here is a stack of distinct, owned assets:
- Roughly 1.9 billion primary-law and practical-guidance documents, classified by an editorial system refined over more than a century (35 million Key Number classifications, plus the headnotes that say what point of law a passage is about);
- 1.4 billion KeyCite signals for whether a case is still good law; and
- Citation ledger that makes every source traceable.
That native access is the advantage, and it is structural. When the agent, Westlaw, Practical Law, and KeyCite sit inside one wall with no integration boundary, a customer’s documents resolve directly against that authority without an API or MCP tool mediating the round trip.
A vendor reaching the same content through a partner integration gets the partner’s answers, but the classification, citator, and canonical metadata stay on the other side. Anyone can extract “California” as a label but a provider that owns both the extraction and the classification it resolves into can land that label on the California Court of Appeal, Second Appellate District, and its line of authority deterministically. That is the difference between a method that reproduces and one that approximates.
A partner integration cannot make that resolution. An MCP connection retrieves the document, but not the underlying Westlaw and Practical Law court taxonomy that disambiguates the Second District from the other California courts the bare label could name. That taxonomy, including the court-hierarchy node that resolves California’s six appellate districts and their divisions, and KeyCite’s classification tying a cited decision to that exact node is not exposed through a standard MCP call.
Grounding into authority: rent across a boundary vs. own the wall
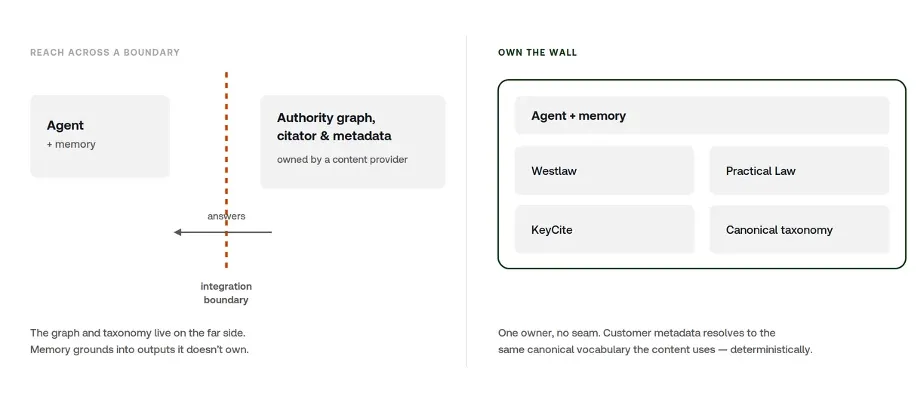
The real difference sits on top of all this. Procedural memory that records how a method actually played out and informs how the next draft is likely to land. Your own matters are the raw material with authority grounding it. Together they form the flywheel, with each grounded matter sharpening the memory system for the next matter.
Deterministic walls: trust without trusting the model
A model can’t be trusted to return the same answer twice, so the parts a lawyer relies on can’t rest on the model alone. The place that matters most, and the one with direct legal consequences, is the ethical wall.
Here “deterministic” is meant literally. When a memory is written, its matter scope and access boundary are computed from the matter’s own metadata and stamped onto the record itself. Every read recomputes the same boundary from that metadata, ensuring no data leakage outside the scoped matter boundary. The isolation is a property of the record, not a filter the model applies on the way out.
That distinction is the critical point. A filter leaves the model as the last line of defense, where a single miss crosses the ethical wall. A write-time barrier makes that miss impossible, where knowledge is never reachable across matters, and every read is traceable with audit trails. This is the lesson from Heppner, made operational, where data lives and who can reach it is a legal requirement.
Deterministic walls: isolation set at write time, enforced on every read

How we’re thinking about it, and where we want your input
We’re sure of the shape: memory held to a fiduciary standard, grounded in authority we own, that learns from your matters and predicts where the next one lands. What isn’t settled is the architecture under it: the graph that holds these relationships, the resolution that connects your documents to authority. We’d rather get that right with the people who’ll use it than announce it finished.
The direction is grounding that resolves your own documents to canonical Westlaw and Practical Law authority, so the good-law signal stays live by design. The payoff is concrete as we have discussed, where having authority to understand when case law is overruled such that it stops being cited next week, automatically, without anyone remembering to check. That’s the staleness failure from earlier, closed at the source. Part two goes inside the how.
We’re building the evaluation for this now, and we’d rather be measured than believed. The table below is how we intend to test these claims rather than assert them.
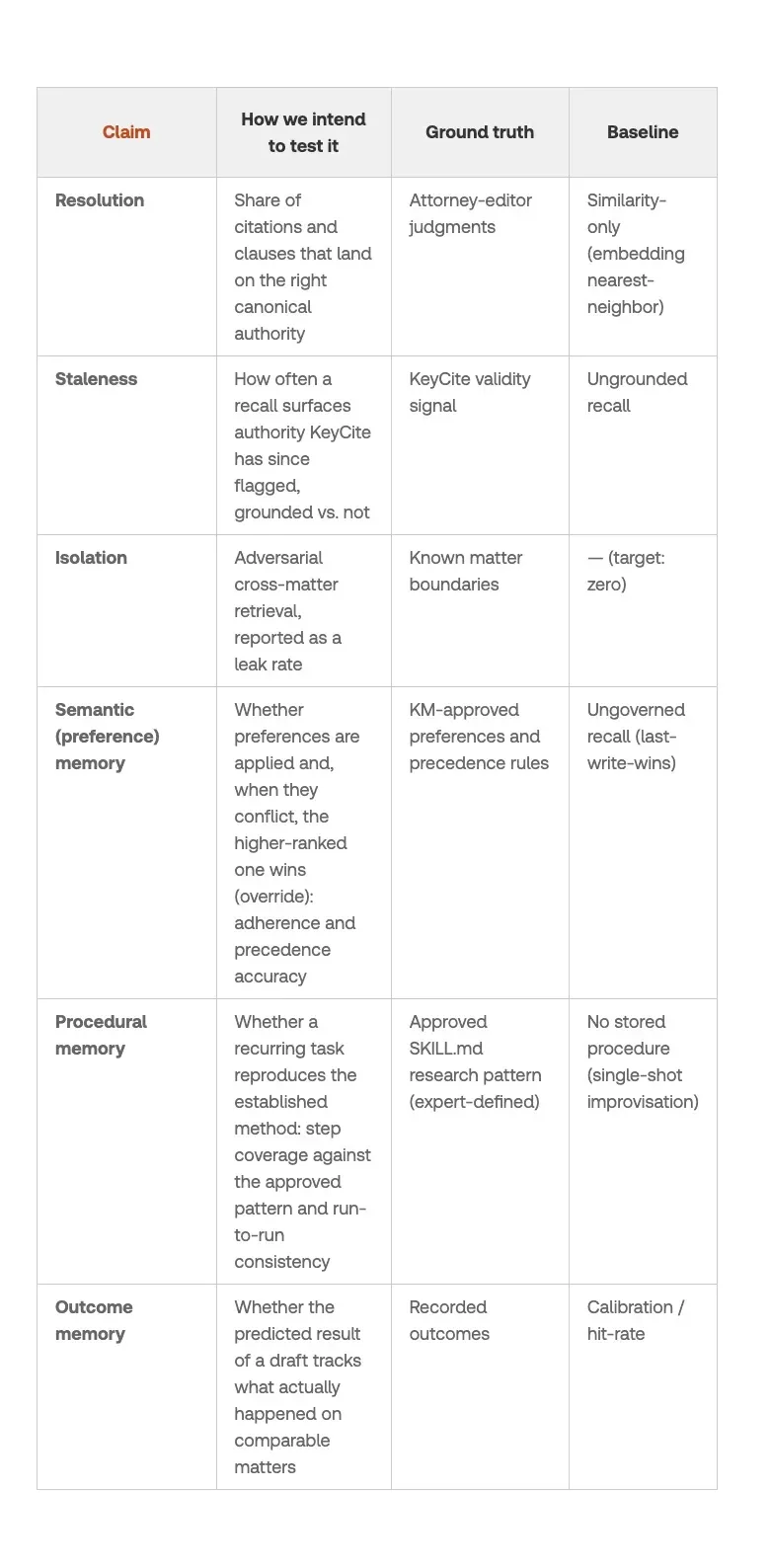
Whether these are the right measures is an open question. We are looking for feedback to guide our work, including KMs and practice leadership at a firm, KMs and legal ops in a department.
Four questions in particular:
- Where should a memory live on the spectrum between a single matter and the entire organization?
- Which procedural patterns earn promotion into a reusable skill and how well grounded in trusted authority and proven across a customer’s matters they must be before they qualify?
- Who signs off on promoted patterns: the KM, or a senior reviewer such as a partner or senior in-house counsel?
- Whether patterns should ever be shared across teams or business units, and on what terms?
These questions will shape how this is built. If you’re interested in connecting more or want a say in the architecture before it’s finished, we want to hear from you.
CoCounsel Legal
Explore the next generation of CoCounsel Legal with memory built to a fiduciary standard
Watch demo ↗Part two of this technical note opens the system:
- How retrieval routes a query and resolves it against the taxonomy,
- How procedural memory is captured and replayed into the next draft,
- How semantic memory (personalization, tone, posture) is captured, governed, and reconciled when entries conflict or drift,
- How durable skills are surfaced for promotion,
- How we keep the system deterministic where it has to be to, such that it is checkable and reproducible, and
- How we measure whether any of it holds through metrics such as recall, precision, and honest abstention.
The worked before/after is one piece of it: a citation or clause resolved to the correct controlling authority and Key Number, set against what a similarity-only baseline returned instead: a passage that read similar but pointed to superseded or off-point authority.
If this note made the case structurally, the next one shows it running.








