
AI streamlines document review and creation, due diligence, legal research, and e-discovery. Work with greater speed, lower costs, and fewer errors.
Highlights
- AI for legal documents leverages technologies such as Natural Language Processing (NLP), Machine Learning (ML), and Large Language Models (LLMs) to analyze, extract, and generate text.
- Such technology enhances efficiency and accuracy across various legal tasks, including rapid document review, comprehensive due diligence, advanced legal research, e-discovery, streamlined document creation, and contract lifecycle management.
- AI in document review and drafting is a tool that requires essential human oversight from expert lawyers to ensure final accuracy and professional judgment.
Legal professionals today face unprecedented demands for efficiency in legal operations, legal cost reduction, and maintaining accuracy in legal documents. And legal tech that recently seemed like science fiction is quickly becoming essential.
Artificial Intelligence (AI) for legal focuses the power of AI on the routine legal tasks that consume much of your time. Setting AI on them frees more of your time for higher-value work. AI for legal documents is a prime example that gives lawyers new tools to meet these demands.
Jump to ↓
What powers AI for legal documents?
Where AI makes a difference in legal documents
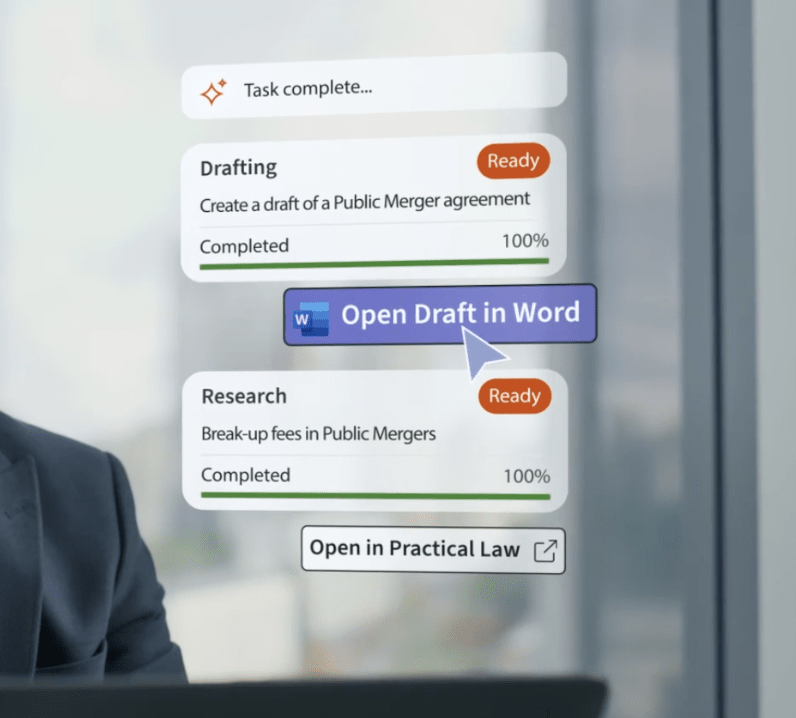
CoCounsel Legal
Work smarter with documents using an all-in-one solution integrated with Westlaw, Practical Law, Microsoft 365, and DMS partners
Go Professional-grade AI ↗What powers AI for legal documents?
Today’s AI goes beyond automating tasks to transforming the way you work. Here’s an overview of the technology:
Demystifying the technology
Natural language processing (NLP) gives AI the ability to interact with people and work with legal documents, where it can extract, analyze, and generate human-like text.
Machine learning in legal contexts enables AI to recognize patterns in the data and documents it processes. It uses these patterns to make its own decisions and recommendations, a big step forward from when computers needed explicit step-by-step instructions.
Large language models (LLMs) in law, which use advanced forms of machine learning, are the cutting edge of AI for complex legal tasks.
How it works
AI systems perform text analytics for legal documents to enable information to be extracted from legal texts. Professional-grade systems trained on large quantities of legal documents learn to identify various features of sections within the documents, such as relevance and privilege.
Once trained, the AI assigns probability scores to the information it finds in the current document set. That could, for example, give lawyers a prioritized list of items to review, bringing order to a previously random process.

Where AI makes a difference in legal documents
AI for legal documents is not only much faster than human-powered work but also promises greater accuracy. It reduces errors by finding relevant information human reviewers might have missed and by identifying and flagging inconsistencies.
Streamlining document review and due diligence
Traditionally, contract review used personnel to sift through large volumes of complex contracts, a time-consuming and costly process prone to errors.
AI can retrieve information from hundreds or thousands of documents in seconds. It searches for meaning and intent, going beyond looking only for keywords and phrases. The summaries it generates in seconds could have taken a junior attorney days or weeks.
AI can also provide actionable insights, including:
- Comparing contracts and other documents, highlighting similarities and differences
- Identifying potential conflicts and other risk factors
- Creating timelines
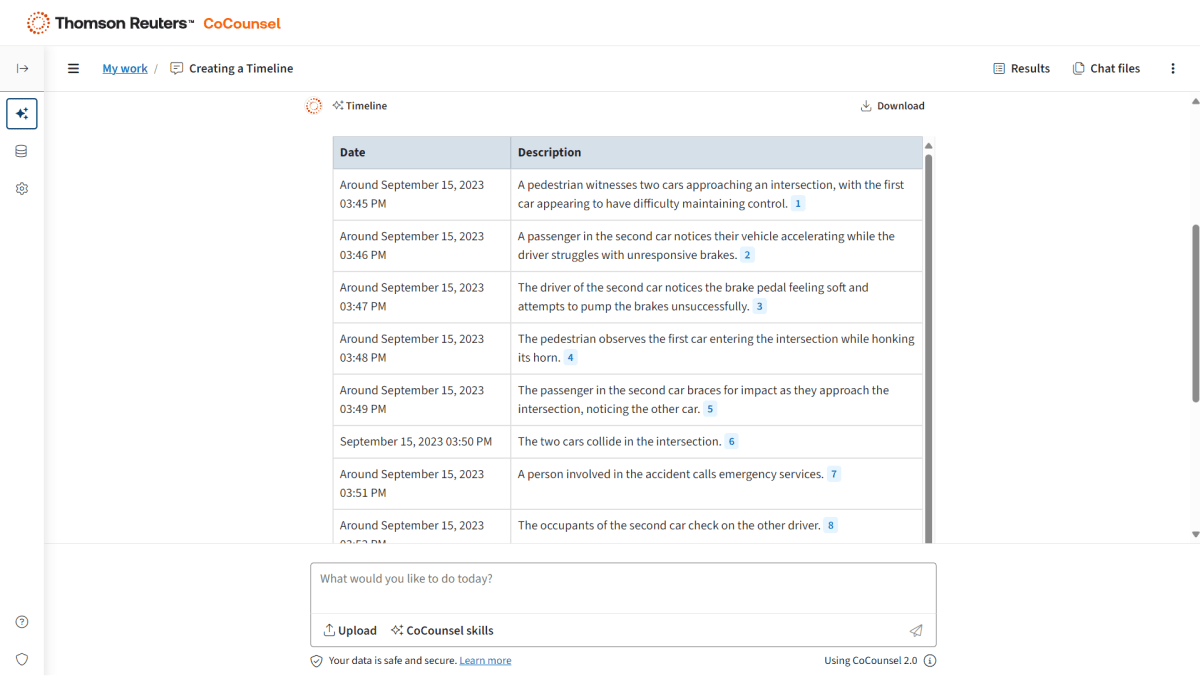
Due diligence AI accelerates complex transactions. Because of due diligence’s tight deadlines and budget restrictions, lawyers working without AI might only be able to review some of the documents, thereby missing important obligations. AI, with its capacity for processing enormous amounts of data, can analyze all the relevant documents and extract essential information, reducing your risk.
Legal research and e-discovery
Professional-grade legal AI can assist with many research functions, including:
- Finding and analyzing case law
- Summarizing and identifying weaknesses in your opponent’s arguments
- Intelligently searching for primary sources
- Extracting key facts and issues
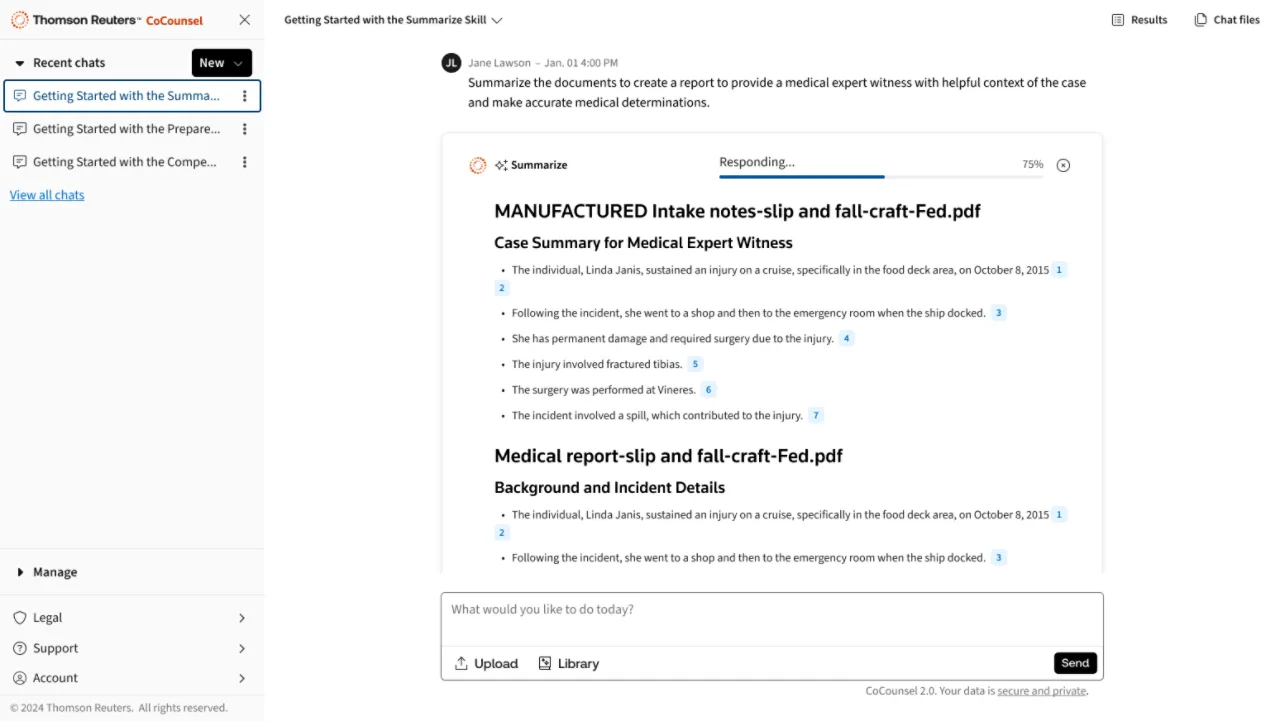
In e-discovery, AI helps manage massive data sets more efficiently. Machine learning enables AI to use predictive coding to identify which documents are most likely to contain relevant information.
Enhancing document creation and management
Besides extracting information from documents, AI excels in helping lawyers create and manage them. Its drafting assistance helps by determining the best starting point, find relevant documents, provide summaries and suggestions, and identify errors and missing information.
AI assists in legal contract management at each stage of a contract’s lifecycle: initiation, negotiation, execution, monitoring, and closure. It can identify missing terms, check compliance, enhance real-time oversight, and speed up processing.
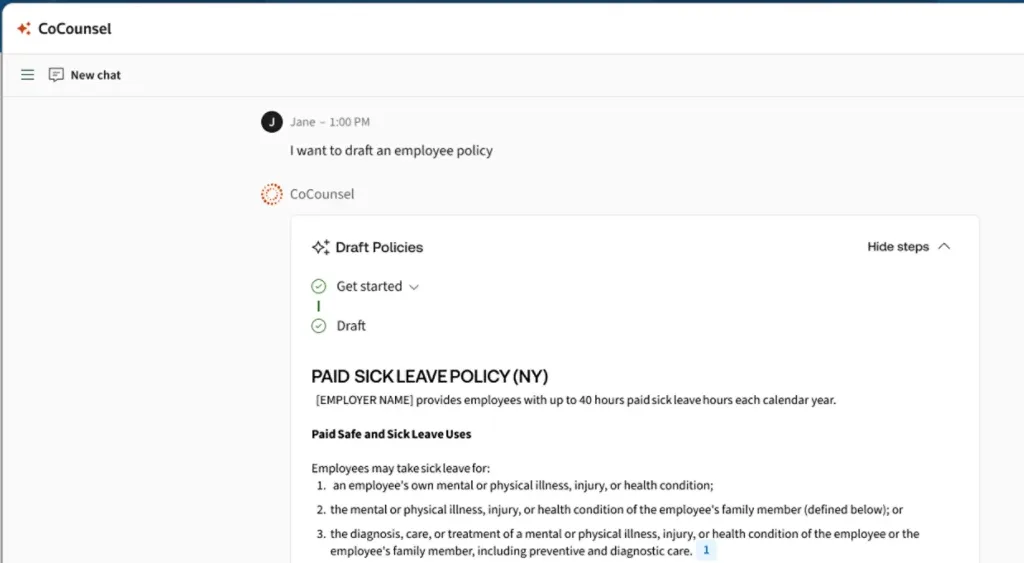
These functions enhance efficiency and accuracy, but they are there to assist, not to take over. AI, for all its abilities, is just a tool. Human oversight by an expert lawyer is essential.

White paper
AI-powered legal drafting: The definitive guide for legal professionals
Read white paper ↗More related resources
AI for legal documents is a powerful technology for many legal applications: document review, due diligence, legal research, e-discovery, document creation and drafting, contract management, and compliance. It can save money, increase accuracy, reduce risk, improve efficiency, free up time for higher-level work, and make your firm more competitive.
We encourage you to explore the transformative power of professional-grade AI and find out all it can do for your practice.
For more related content about AI in the working profession, see also:
- What to know and do about generative AI for legal professionals
- Everywhere you are: Enhancing legal productivity with CoCounsel
- Don’t want to become a “ChatGPT lawyer”?
CoCounsel Legal
AI lawyers swear by: Trusted content, expert insights, and an all-in-one solution with ISO 42001 certification
See it in action ↗







